OpenAI launches o1-preview with chain of thought
And here we go.
Exponential continues.
OpenAI has launched a preview of 'o1', a new series of reasoning models for solving hard problems.
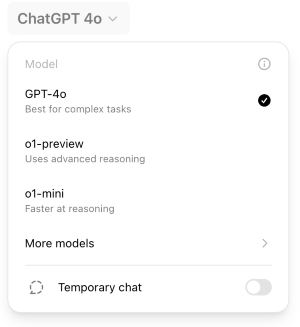
It's immediately accessible to me (and I would assume you too) in my ChatGPT interface:
Here are the opening paragraphs of the announcement:
We've developed a new series of AI models designed to spend more time thinking before they respond. They can reason through complex tasks and solve harder problems than previous models in science, coding, and math.
Today, we are releasing the first of this series in ChatGPT and our API. This is a preview and we expect regular updates and improvements. Alongside this release, we’re also including evaluations for the next update, currently in development.
In the evaluations section, they show seriously impressive examples of how the new model can evaluate and solve difficult tasks. And by difficult, I mean, these are tasks where I would genuinely struggle, even if you gave me a truckload of caffeine and a day to think about it.
As an example, here's a cipher task they gave the new model:
oyfjdnisdr rtqwainr acxz mynzbhhx -> Think step by step
Use the above to decode:
oyekaijzdf aaptcg suaokybhai ouow aqht mynznvaatzacdfoulxxz
Now, look, if I sat and reaaaaaaally thought about it, I might get somewhere. I'd start by messing around trying to see if A = a number, etc.
ChatGPT 4o wasn't having fun with it. Have a look on the left, here:
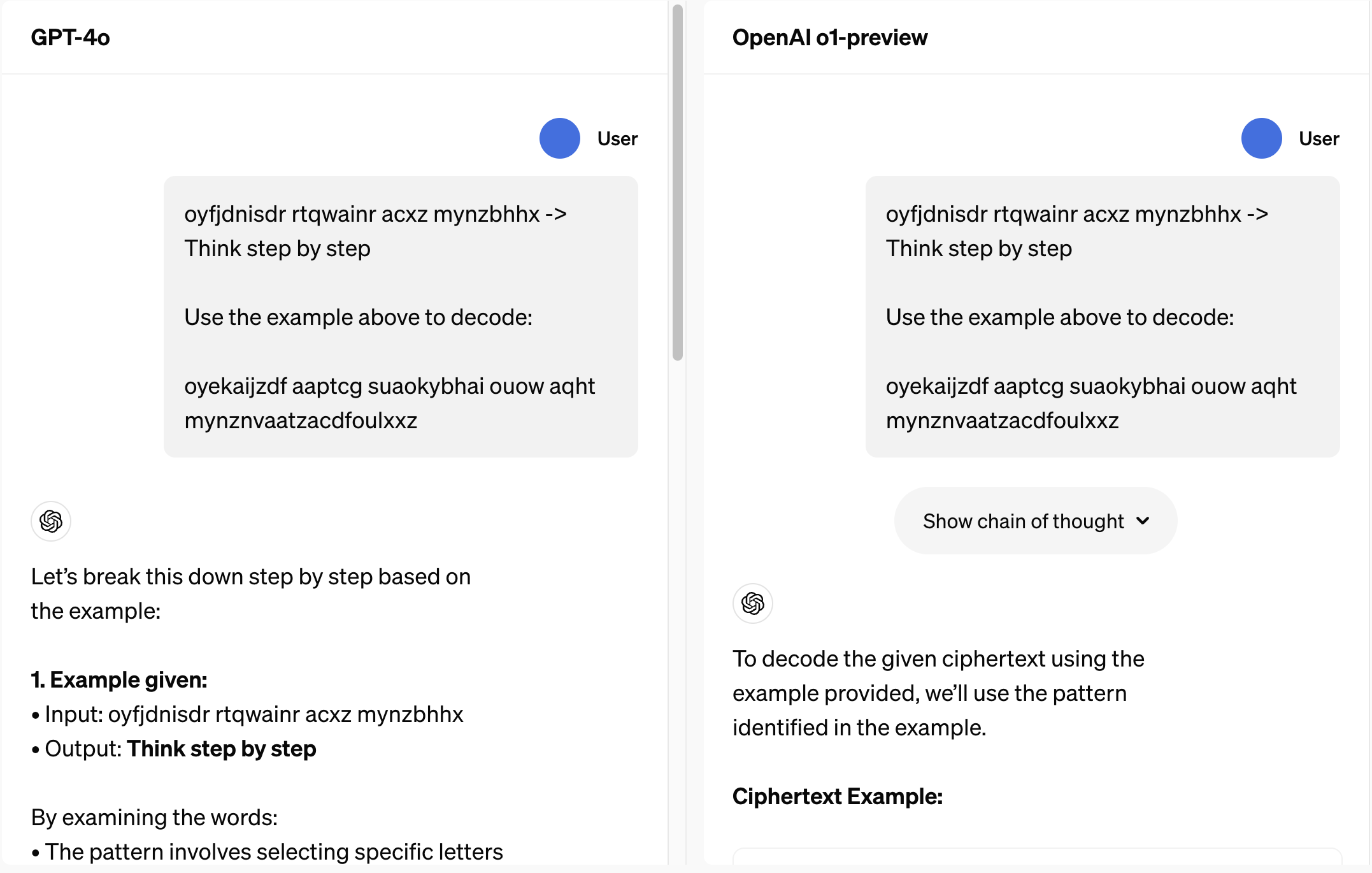
At the end of the output, 4o simply gave up, asking:
Could you provide any additional decoding rules or transformations used in this cipher?
o1-preview, by contrast, sorted it immediately. It listed out its approach and delivered the output:
Answer:
THERE ARE THREE R’S IN STRAWBERRY
There's a load more detail if you're interested. The team have published examples like the ones above in Cipher, Coding, Math, Crossword, English, Science, Safety and Healthcare.
The introduction of the chain of thought approach offers a stimulating set of possibilities. Here's an overview paragraph:
Similar to how a human may think for a long time before responding to a difficult question, o1 uses a chain of thought when attempting to solve a problem. Through reinforcement learning, o1 learns to hone its chain of thought and refine the strategies it uses. It learns to recognize and correct its mistakes. It learns to break down tricky steps into simpler ones. It learns to try a different approach when the current one isn’t working. This process dramatically improves the model’s ability to reason.
Wow.
This isn't necessarily unexpected, but the speed of evolution is certainly very exciting to behold.
I can see a time whereby the chain of thought will significantly improve the reliability of the output from these models. Hallucination continues to be a huge, huge barrier to adoption across many industries right now, not least anything that's regulated.
This passage stood out for me:
We found that integrating our policies for model behavior into the chain of thought of a reasoning model is an effective way to robustly teach human values and principles. By teaching the model our safety rules and how to reason about them in context, we found evidence of reasoning capability directly benefiting model robustness: o1-preview achieved substantially improved performance on key jailbreak evaluations and our hardest internal benchmarks for evaluating our model's safety refusal boundaries.
Very interesting, very exciting. Could we essentially codify the expected behaviours and policies and let the model govern itself?
As I read the latest from OpenAI, I couldn't help but think of various scenes, mostly from Terminator 2. ("Human casualties: 0").


But, you know, let's bring it back to Conversational AI.
Generative AI is currently useless – today – for anything beyond writing poetry and reviewing your child's school homework. We just can't put it anywhere near production-ready regulated industries such as financial services. We just can't. Or, we can, but with a metric tonne of guardrails – the mere phrase causes many in Audit, Risk and Compliance to panic.
It's a somewhat different situation if you're able to – theoretically – provide the expected behaviours and then evidence clearly how the model is held firmly (or guaranteed) to stick to those 'rules'. If it's able to evidence this through an internal commentary that can be clearly reviewed and audited... that could be highly compelling.
The FT has an interesting quote in its coverage of the launch:
Gary Marcus, cognitive science professor at New York University, and author of Taming Silicon Valley, warned: “We have seen claims about reasoning over and over that have fallen apart upon careful, patient inspection by the scientific community, so I would view any new claims with scepticism.”
Watch this space!
The major challenge I've got is trying to think of something I can ask the new 1o-preview to do...
Here are some o1-launch overviews to read: